调试 Firefox 浏览器发起的网络请求
- 在地址栏输入
about:debugging - 点击
This Firefox - 找到目标扩展 → 点击
Inspect(调试) - 在新打开的开发者工具中,切换到 Network 面板,即可看到该扩展发起的请求
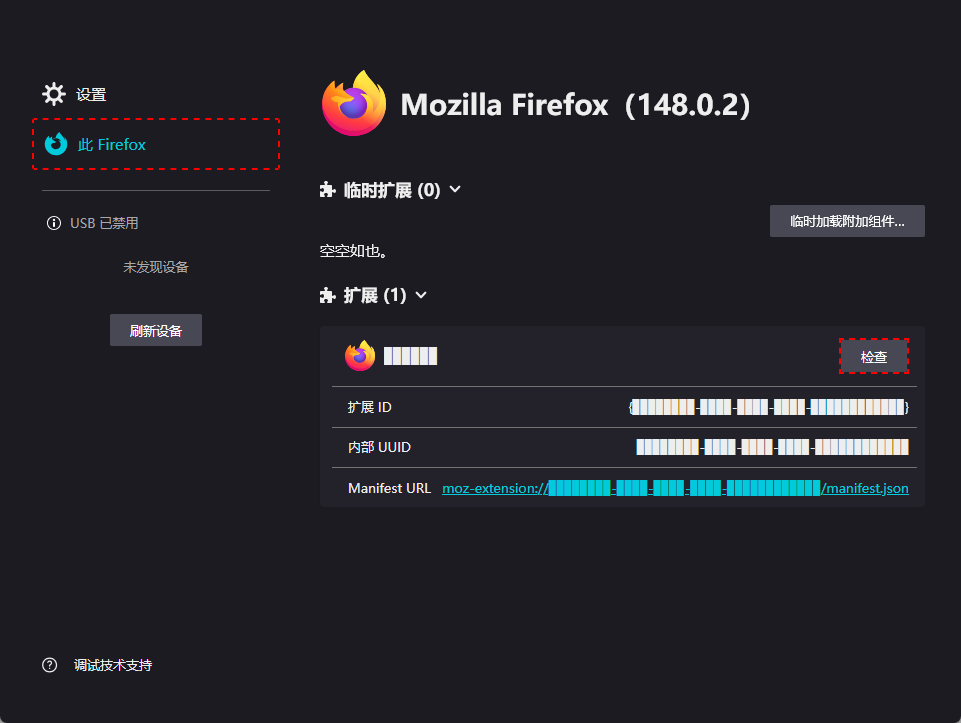
about:debuggingThis FirefoxInspect(调试)
最近在搞一个 Vue3 + Vite 的项目,想着给项目加上 ESLint,结果发现 ESLint 现在推荐用新的 flat config 格式了,跟之前那种 .eslintrc.js 的写法完全不一样。折腾了一阵子终于搞定,记录一下配置过程,希望能帮到同样遇到这个问题的小伙伴。
首先当然是装 ESLint 和相关插件啦:
1 | npm install -D eslint @eslint/js eslint-plugin-vue |
这里简单说一下装的几个包都是干啥的:
eslint - ESLint 核心,不用说eslint/js - JavaScript 官方推荐的规则集eslint-plugin-vue - Vue 官方的 ESLint 插件,专门检查 Vue 组件的ESLint 现在推荐使用 flat config 格式,配置文件名是 eslint.config.js,写法跟以前差别挺大的。
1 | import js from '@eslint/js' |
这里有几个坑说一下:
第一个坑:一定要在配置里声明浏览器全局变量!不然 ESLint 会报 localStorage is not defined 之类的错误。上面配置里的 globals 就是干这个的。
第二个坑:ignores 要放在第一个配置对象里单独写,不能跟其他配置混在一起。
自定义规则说明:
vue/multi-word-component-names: 'off' - 这个规则要求组件名必须是多单词的,我习惯用单词组件名,干脆关掉了vue/no-v-html: 'warn' - 用 v-html 有 XSS 风险,改成 warn 提醒自己注意no-unused-vars - 未使用变量改成警告,argsIgnorePattern: '^_' 表示以 _ 开头的参数可以忽略(有时候回调函数的参数不用但又必须写在前面)在 package.json 里加上:
1 | { |
这样就可以用 npm run lint 检查代码,用 npm run lint:fix 自动修复能修的问题。
光有命令行检查还不够,开发的时候能实时看到问题更方便。装个 vite-plugin-eslint:
1 | npm install -D vite-plugin-eslint |
然后在 vite.config.js 里加上:
1 | import eslint from 'vite-plugin-eslint' |
这样 Vite 开发服务器启动后,代码有问题会直接在页面上弹出来,再也不用手动跑 lint 命令了。
有时候复制代码会带上中文全角空格,ESLint 会报 no-irregular-whitespace。这个一般 IDE 能看出来,注意一下就行。
no-unused-vars 这个规则经常会报,比如:
1 | // 报错:nextTick 未使用 |
如果有些变量确实暂时不用但想留着,可以在变量名前加个下划线 _,因为上面配置了 argsIgnorePattern: '^_'。
ESLint 配置这东西,一开始看着挺麻烦的,配好之后真的能避免很多低级错误。尤其是多人协作的项目,统一代码风格太重要了。flat config 虽然写法变了,但配置逻辑其实更清晰了,习惯了就好。
如果这篇对你有帮助,欢迎留言交流~
最近在写项目的时候用到了 Element Plus 的下拉菜单组件 el-dropdown,本来挺好用的,但是每次鼠标悬浮或者点击的时候,总会冒出来一个黑色的边框,看着特别别扭。
这个边框其实是浏览器自带的焦点样式,就是那种 tab 切换时候会显示的轮廓线。虽然从可访问性的角度来说这是个好东西,但有时候跟设计稿对不上,还是得把它干掉。
其实很简单,就是用 CSS 把 outline 去掉就行。但是因为 el-dropdown 内部的样式是 scoped 的,所以得用样式穿透才能生效。
1 | :deep(.el-tooltip__trigger:focus) { |
这里要注意一下,el-dropdown 内部触发下拉的元素有个 el-tooltip__trigger 类,我们就是要把这个类上的焦点样式去掉。
如果你还在用 Vue 2 的话,写法稍微有点不一样:
1 | ::v-deep .el-tooltip__trigger:focus-visible { |
顺便说一下 outline 和 border 的区别吧,刚开始学 CSS 的时候老搞混:
outline 不占空间,画在元素外面,不影响布局border 占空间,会影响元素的尺寸所以这个焦点边框才会”凭空出现”,不会把页面撑开或者挤跑其他元素。
放一段完整的代码,方便直接复制:
1 | <template> |
这个小问题当时还是让我找了一会,因为一开始不知道要穿透的类名是 el-tooltip__trigger,一直在 el-dropdown 那里瞎折腾。希望能帮到同样遇到这个问题的小伙伴~
最近做项目要发邮件,什么注册确认、密码重置、订单通知,一堆功能都离不开邮件。PHP 自带的 mail() 函数?说实话,用过的都知道有多坑——配置麻烦、兼容性差、容易被当垃圾邮件。最后还是老老实实用 PHPMailer,踩了一些坑,今天把经验整理一下。
PHPMailer 是 PHP 里最老牌的邮件发送库,功能齐全:
环境要求:PHP 5.5 ~ 8.3,需要开启 mbstring 和 openssl 扩展。
推荐用 Composer,省心:
1 | composer require phpmailer/phpmailer |
不想用 Composer 也行,去 GitHub 下载源码,手动引入文件。但都 2026 年了,还是 Composer 吧。
发邮件得有 SMTP 服务器,常用的 163 和 QQ 邮箱配置如下:
| 邮箱 | SMTP 服务器 | SSL 端口 |
|---|---|---|
| 163 | smtp.163.com | 465 或 994 |
| smtp.qq.com | 465 或 587 |
重要提醒:163、QQ 这些邮箱默认关闭 SMTP 服务,得去邮箱设置里手动开启,然后生成一个「授权码」。后面代码里的密码填的是授权码,不是你的登录密码!
直接上代码,能跑的才是好教程:
1 |
|
加附件一行代码的事:
1 | $mail->addAttachment('/path/to/file.zip'); // 普通附件 |
注意路径要写对,相对路径、绝对路径都行,但要确保文件存在。
想在邮件正文里显示图片,有两种方式:一种是用 <img src="cid:图片id"> 配合 addEmbeddedImage,另一种是直接 base64 编码嵌入。推荐前者:
1 | $mail->Body = '<h1>你好</h1><img src="cid:logo">'; |
最常见的错误。原因可能是:
大概率是密码填错了。163、QQ 邮箱要用授权码,不是登录密码。授权码在邮箱设置里生成。
编码问题,加上这句:
1 | $mail->CharSet = "UTF-8"; |
检查 PHP 有没有开启 openssl 扩展,php.ini 里把 extension=openssl 前面的分号去掉,重启服务。
原因很多:发件人和 SMTP 认证邮箱不一致、邮件内容太像广告、域名没有配置 SPF 记录。生产环境建议用专业邮件服务,比如 SendGrid、Mailgun,比自己搭 SMTP 靠谱。
开发阶段遇到问题,打开调试模式:
1 | $mail->SMTPDebug = 2; // 级别 0-4,数字越大越详细 |
调试完记得关掉,生产环境开调试会暴露敏感信息。
把上面的拼起来:
1 |
|
PHPMailer 用起来其实不难,主要是 SMTP 配置容易踩坑。记住几个要点:授权码、端口、编码、调试模式,基本就能搞定大部分场景了。
有问题欢迎评论区交流~
最近有个需求,要定时截取几个网页的页面截图,还得把动态加载的内容也截进去。一开始用 PHP 的 file_get_contents 和 cURL 抓,结果发现那些内容是 JavaScript 渲染出来的,抓回来全是空白。折腾半天,最后找到了 chrome-php 这个库,用 PHP 直接控制 Chrome 浏览器,问题迎刃而解。

身为开发者,日常在编码时,是不是常被输入法切换问题困扰?写代码时得用英文输入法,添加注释又得切换成中文输入法。反复按 Shift 键或使用组合快捷键,不仅麻烦,还容易打断思路。有时候,因为没注意输入法状态,输入一半才发现错了,只能删除重新输入 ,实在让人抓狂。
Smart Input Pro 就是一款专为解决这些痛点而生的插件,基于 IntelliJ 平台,在 IDEA、WebStorm、PyCharm 等这些大家日常开发常用的工具中,都可以安装使用。它就像一个贴心的智能助手,时刻监控你的输入场景,然后自动帮你在中英文输入法之间进行切换,从此你再也不用手动频繁切换输入法了。
Smart Input Pro 之所以能实现如此智能的切换,得益于其 “场景感知 + 智能决策” 的先进架构。它就像一个聪明的观察者,会实时分析多个关键因素:
光标位置:精确判断你当前输入的位置是在代码区、注释区,还是字符串内。
代码上下文:理解代码的语法结构,知道哪些地方应该是英文代码,哪些地方是中文注释 。比如,当它检测到你在注释区域(单行注释//、多行注释/* */、文档注释/** */ )时,就会自动切换至中文输入法,方便你撰写说明;而在代码区域,则自动切换至英文输入法,确保代码语法正确。
操作行为:留意你的操作动作,比如当你打开 Git 提交框准备填写提交信息时,它能识别提交框焦点,自动切换为中文输入法;当你使用 IdeaVim 模式时,在 NORMAL 模式下自动切换英文,确保命令正确执行。
通过综合分析这些因素,插件能够动态匹配最优输入法,整个过程自然流畅,让你在不知不觉中完成输入状态的切换,将全部的注意力都集中在代码逻辑本身,极大地提升了编码效率和专注度 。
Smart Input Pro 的场景化自动切换功能十分强大,能精准识别各种输入场景,自动帮你切换到最合适的输入法 。
在代码编辑区,当你进入代码编写区域时,插件会迅速反应,自动切换为英文输入法,杜绝中文输入法下误输入全角符号(如 “,”“。”)导致的编译错误,为代码的准确性提供保障。它支持 JavaScript、Java、Vue 等主流语言,对字符串字面量还能进行智能识别。比如,当你输入nameEn="Tom" 时,它能判断这里应保持英文;而当输入nameCn="小明" ,则会自动唤醒中文 ,就像一个熟悉你代码习惯的伙伴,默默帮你处理好输入法的细节。
来到注释与文档区,当你输入单行注释(//)、多行注释(/**/)或 Markdown 文档时,它又会贴心地自动切换为中文输入法,而且完美兼容中英文混合输入场景,让注释撰写无比流畅。以编写 Javadoc 为例,中文描述与英文代码符号能在它的帮助下无缝衔接,你可以专注于内容表达,无需再为输入法切换分神 。
除了上述区域,在工具窗口与特殊场景中,它也能发挥作用。比如在 Git 提交框,当你输入 Commit Message 时,它自动切为中文,方便你规范地撰写中文提交说明;在终端(Terminal)/Project 窗口,它会强制英文输入,避免命令行中混入中文字符,保证命令执行顺畅;如果你使用 IdeaVim 模式,在 NORMAL 模式它自动切换为英文,INSERT 模式则按当前编辑场景智能切换,让 Vim 操作与输入法切换配合默契 。
为了让你随时了解当前的输入状态,Smart Input Pro 还提供了可视化状态反馈功能。
其中,三色光标提示十分直观,蓝色光标代表英文小写,紫色光标表示英文大写,红色光标则意味着中文输入 。在编码过程中,你无需将视线移至系统状态栏,只要看一眼光标颜色,就能快速确认输入状态,大大减少了误操作的概率。比如,当你看到红色光标时,就知道当前是中文输入法状态,可以放心输入中文内容;而看到蓝色光标,就明白现在适合输入英文代码 。
此外,还有轻量浮动标签,它会在光标附近显示 “EN” 或 “中文” 微型标签,这个标签支持自定义位置与透明度。你可以根据自己的习惯,将它调整到既不遮挡视线,又能轻松看到的位置,还能根据个人喜好设置透明度,兼顾提示性与无干扰性,让你在编码时随时掌握输入状态 。
每个人的编码习惯和项目需求都有所不同,Smart Input Pro 充分考虑到这一点,提供了高度可定制化的功能。
通过自定义正则匹配,你可以轻松定义特殊场景。例如,针对 i18n 相关文件(*.zh-CN.vue),你可以通过正则表达式让插件强制中文输入,确保国际化文件中的中文内容输入顺畅;或者在 SQL 脚本中,识别中文注释块并自动切为中文,满足特定的编程需求 。只需要简单编写正则表达式,就能让插件按照你的想法工作 。
它还有强大的输入法记忆机制。当你手动切换输入法后,插件会自动学习你的习惯。比如,在特定文件类型中,你偏好某种输入状态,它就会记住这个习惯,逐步优化切换策略,随着使用时间的增加,它会越来越 “懂你” ,让输入法的切换更加贴合你的使用习惯,为你打造个性化的编码输入环境 。
安装 Smart Input Pro 的过程非常简单,无论你是在线安装还是离线安装,都能轻松完成。
如果你选择在线安装,在 IDE 内打开插件市场,这就好比是一个插件的大超市,里面摆满了各种各样的插件 。在搜索框中输入 “Smart Input Pro”,就像在超市里寻找特定的商品一样,很快就能找到它。找到后,点击安装按钮,插件就会自动下载并安装到你的 IDE 中。安装完成后,按照提示重启 IDE,整个过程无需手动配置,就像拿到一个新的电子产品,打开就能用,真正做到了开箱即用 。
要是你处于网络受限的环境,也不用担心,还可以选择离线安装。你可以从 JetBrains 插件市场下载对应版本的 ZIP 文件,这个文件就像是一个装满插件的包裹 。下载好后,通过 “Install Plugin from Disk”(从磁盘安装插件)选项将下载的 ZIP 文件导入到 IDE 中,就像把包裹里的东西放进你的电脑里一样简单,轻松解决网络问题带来的困扰 。
安装完成后,还需要进行一些基础配置,让插件更好地适应你的使用习惯 。
首先是选择默认中文输入法,在插件设置中,你可以指定自己常用的中文输入法,比如大家常用的搜狗输入法、百度输入法等 。这就像是给插件设定一个语言助手,让它知道你平时喜欢用哪种中文输入法,这样它就能在需要的时候精准地帮你切换,确保输入法的切换符合你的习惯 。
对于不同系统的用户,它还有一些专属的跨平台适配设置。Windows 用户可以启用 “离开 IDE 恢复系统输入法” 功能,当你离开 IDE 去做其他事情,再回到 IDE 时,输入法会自动恢复到你离开前在 IDE 中的设置,就像 IDE 记住了你离开时的输入法状态一样 。而 Mac 用户则更方便,插件支持全局输入法状态记忆,当你在不同应用之间切换时,它会自动还原你的输入环境,比如你从 IDE 切换到浏览器,再切回 IDE,输入法还是你在 IDE 中使用时的状态,让你的输入体验更加流畅 。
如果你想要进一步发挥插件的强大功能,还可以进行进阶设置 。
通过自定义场景规则,你可以打造适合自己的输入逻辑。进入 “Settings> Smart Input Pro > Custom Rules”(设置 > Smart Input Pro > 自定义规则),在这里,你可以针对特定的文件路径、代码块结构添加专属的切换逻辑 。比如,在一个 Vue 项目中,你希望 Vue 模板中的中文文案区域始终保持中文输入,就可以在这里进行设置。通过编写规则,让插件识别 Vue 模板文件,当光标进入中文文案区域时,自动切换并保持中文输入法状态,让你的代码编写更加高效 。
对于使用低配设备的开发者,为了平衡智能度与流畅度,还可以开启 “轻量模式” 。开启后,插件会降低资源占用,就像给插件 “瘦身” 一样,让它在低配设备上也能轻松运行,不会因为占用过多资源而导致设备卡顿,让你在享受智能输入的同时,也能保证设备的流畅运行 。
为了让大家更直观地感受到 Smart Input Pro 带来的效率提升,我们来看一下实际开发场景中使用插件前后的对比 。
在未使用插件之前,开发过程中充满了各种因输入法切换带来的困扰。就拿编写代码来说,平均每 5 分钟,我就会因为输入法的问题而出现 1 次输入状态错误。比如在定义变量名时,本应使用英文输入法输入字母,却因为疏忽还停留在中文输入法状态,结果输入了全角字符,导致代码出现语法错误 。在添加注释时,也经常会因为没有及时切换输入法,使得注释中混入英文符号,或者在代码中出现中文标点,这不仅影响了代码的可读性,还需要花费额外的时间去反复检查修正 。
而使用 Smart Input Pro 插件后,情况就大不一样了 。在代码区,它会自动切换为英文输入法,确保我输入的代码准确无误;在注释区,又会自动切换为中文输入法,让我可以流畅地撰写注释 。就连在 Git 提交时,也无需手动切换输入法,直接就能用中文输入提交信息 。根据我的统计,使用插件后,日均减少了 200 + 次无效切换操作,编码时的专注度也提升了 30% ,真正实现了从低效到高效的转变 。
接下来,以 Vue 开发为例,为大家详细演示一下 Smart Input Pro 插件的具体使用过程 。
在<template>标签内编写代码时,当我输入v-model,准备补全变量名,此时插件会保持英文输入法状态,让我可以毫无干扰地输入英文变量名 。比如输入v-model="userName" ,整个输入过程非常流畅,不用担心输入法的问题 。
当切换到<script>的注释区域,我输入// 按钮点击事件 ,插件会自动切换为中文输入法,我可以直接输入中文描述,快速完成注释内容的编写 。像// 点击按钮后,调用接口获取数据 ,轻松就能完成输入 。
当打开 Git 提交窗口,准备输入提交信息时,比如输入 “修复表单验证逻辑” ,此时无需手动切换输入法,因为插件已经自动将输入法切换为中文,直接输入即可,大大提高了提交效率 。
进入终端输入npm run dev时,插件会强制将输入法切换为英文,避免因为误输入中文而导致命令错误 。即使我不小心按下了中文输入法快捷键,插件也能迅速调整回来,确保命令的正确执行 。
效率提升显著:在日常开发中,我们常常会因为频繁切换输入法而打断思路,降低编码效率 。而 Smart Input Pro 的自动切换功能十分强大,它能够覆盖 90% 以上的常规场景,让我们无需手动切换输入法,从而将更多的时间和精力投入到代码的编写中。以我个人的使用体验为例,在使用该插件之前,我每天需要花费大量的时间在输入法切换上,而使用之后,这些时间被节省了下来,我可以更加专注地思考代码逻辑,编码效率得到了大幅提升 。
错误预防能力:在代码编写过程中,因符号错误导致的编译问题是我们经常会遇到的困扰 。而 Smart Input Pro 通过场景化输入法控制,能够有效地避免这类问题的发生。它会在我们输入代码时,自动切换为英文输入法,确保我们输入的符号都是正确的;而在输入注释时,又会自动切换为中文输入法,方便我们撰写注释 。根据实际使用情况统计,使用该插件后,因符号错误导致的编译问题降低了 80%+,大大提高了代码的质量和开发效率 。
学习成本极低:对于开发者来说,学习新工具的成本是一个重要的考虑因素 。而 Smart Input Pro 的默认配置即满足多数需求,即使是初次使用的用户,也能快速上手。对于一些进阶功能,它还提供了图形化界面操作,我们只需要通过简单的设置,就能轻松实现个性化的需求,无需编写复杂的规则 。这使得我们能够在短时间内熟练掌握插件的使用方法,快速提升编码效率 。
硬件兼容性:在配置较低的电脑上,当我们处理复杂项目时,Smart Input Pro 可能会出现轻微光标延迟的情况 。这是因为插件在运行过程中需要占用一定的系统资源,而配置较低的电脑可能无法满足其需求 。不过,我们可以通过开启轻量模式来缓解这一问题。轻量模式下,插件会降低对系统资源的占用,从而提高运行的流畅度 。虽然开启轻量模式后,插件的一些智能功能可能会受到一定影响,但对于配置较低的电脑用户来说,这仍然是一个不错的解决方案 。
高级功能付费:Smart Input Pro 的高级功能,如自定义正则匹配、多设备同步等,需要订阅专业版才能使用 。对于一些对功能要求较高的用户来说,这可能会增加一定的使用成本 。专业版的月费约 10 元,虽然价格不算高,但对于一些个人开发者或小型团队来说,可能还是会有些犹豫 。不过,免费版已经包含了核心切换功能,能够满足大多数用户的日常需求 。如果用户对高级功能的需求不是很迫切,那么使用免费版也完全可以 。
中文开发者:如果你是一位中文开发者,日常开发中需要频繁在代码与中文注释、文档间切换,那么 Smart Input Pro 绝对是你的得力助手。它能自动识别输入场景,在代码区自动切换为英文输入法,在注释和文档区自动切换为中文输入法,让你无需手动切换,专注于代码的编写和逻辑的实现 。尤其是对于 Java、前端、全栈等领域的开发者,这款插件的实用性更强,能够有效提高你的开发效率 。
效率敏感型开发者:对于那些追求高效开发,希望减少重复性操作,将更多精力聚焦于逻辑实现而非工具切换的人群来说,Smart Input Pro 无疑是一个绝佳的选择 。它的自动切换功能能够极大地减少无效操作,让你在编码过程中保持流畅的思路,将更多的时间和精力投入到真正有价值的工作中 。
Vim/Emacs 用户:如果你是 Vim/Emacs 用户,在使用 IDEA 等开发工具时,常常被 IDE 快捷键与输入法切换间的频繁冲突所困扰,那么 Smart Input Pro 可以完美解决你的问题 。它能够与 IdeaVim 等模式完美适配,在 NORMAL 模式下自动切换英文,确保命令正确执行;在 INSERT 模式下则按当前编辑场景智能切换,让你的 Vim 操作与输入法切换配合得更加默契 。
在 Windows 11 下使用 WSL2 开发 PHP 项目时,断点调试是提升效率的关键。本文将详细讲解如何基于 Alpine Linux v3.18 配置 PhpStorm + XDebug 环境,解决版本兼容、路径映射、调试连接等核心问题,适用于 Hyperf、Laravel 等主流 PHP 框架。
先明确本地开发环境的核心信息,避免后续配置因版本不匹配导致失败:
| 组件 | 版本/信息 | 说明 |
|---|---|---|
| 宿主机系统 | Windows 11 | 需已启用 WSL2(需先开启虚拟机平台功能) |
| WSL2 发行版 | Alpine Linux v3.18 | 已更换阿里云源(安装速度更快) |
| PHP 版本 | 8.1.2 | 需与 XDebug 版本兼容 |
| XDebug 版本 | 3.2.2 | 对应 PHP 8.1 的 PECL 包 |
| 调试框架示例 | Hyperf 3.x | 也适用于 Laravel、ThinkPHP 等 |
| PhpStorm 版本 | 2023.x 及以上 | 确保支持 XDebug 3.x |
在开始配置前,需完成以下基础操作:
wsl 命令启动。1 | # 编辑源配置文件 |
php -v,确保输出 PHP 8.1.2 信息(若未安装,需先通过 apk add php81 php81-cli php81-common 安装)。XDebug 需通过 Alpine 的 PECL 仓库安装,且必须选择与 PHP 版本匹配的包(PHP 8.1 对应 php81-pecl-xdebug)。
先确认仓库中是否有对应 PHP 版本的 XDebug:
1 | apk search xdebug |
输出结果中需包含 php81-pecl-xdebug-3.2.2-r0(若显示 php82-* 则为 PHP 8.2 版本,请勿安装,避免版本不兼容)。
执行安装命令,Alpine 会自动处理依赖:
1 | apk add php81-pecl-xdebug |
安装成功后,执行以下命令验证是否加载 XDebug 扩展:
1 | php -v |
若输出中包含 with Xdebug v3.2.2,说明安装成功:
1 | PHP 8.1.2 (cli) (built: Feb 1 2023 12:05:42) (NTS) |
XDebug 3.x 与 2.x 配置差异较大,需编辑专属配置文件,核心是指定「调试模式」「宿主机地址」「端口」。
Alpine 中 PHP 8.1 的 XDebug 配置文件路径固定为:
1 | vi /etc/php81/conf.d/50_xdebug.ini |
将以下内容复制到文件中,每个配置项都有详细注释,无需额外修改(host.docker.internal 是 WSL2 内置的「宿主机 IP 别名」,无需手动查宿主机 IP):
1 | ; 启用 XDebug 扩展(必须放在最前面) |
配置后需重启 PHP 服务(若用 Hyperf 等框架,重启服务即可),并执行以下命令确认配置:
1 | php -i | grep XDebug |
输出中需包含 xdebug.mode => debug,develop xdebug.client_port => 9003 等信息,说明配置正确。
需在 WSL 中设置 PHP_IDE_CONFIG 环境变量,指定 PhpStorm 中配置的「服务器名称」,确保路径映射生效。
执行以下命令,将环境变量添加到 ~/.bashrc(若用 Zsh 则改为 ~/.zshrc):
1 | # 写入环境变量(SomeName 可自定义,后续 PhpStorm 需用相同名称) |
执行 echo $PHP_IDE_CONFIG,输出 serverName=SomeName 即成功。
PhpStorm 需配置「PHP 解释器」「服务器」「XDebug 端口」,核心是解决「WSL 路径与 Windows 路径映射」问题(断点不命中的常见原因)。
File > Settings > PHP(Windows/Linux)或 PhpStorm > Settings > PHP(Mac)。... → 点击左上角 + → 选择「From Docker, Vagrant, WSL, Remote…」。/usr/bin/php81)→ 点击「OK」。File > Settings > PHP > Servers → 点击左上角 +,配置以下信息:SomeName(必须与 WSL 中 serverName 一致!)。127.0.0.1,Laravel 项目可能为 localhost)。9501,Laravel 默认 8000)。XDebug。D:\projects\hyperf-demo)。/home/user/hyperf-demo)。File > Settings > PHP > Debug > XDebug。9003(与 WSL 中 xdebug.client_port 一致)。PhpStorm 需要主动「侦听」WSL 发送的调试请求,步骤如下:
Shift + F9。在 Windows 中打开「命令提示符(CMD)」,执行以下命令查看 9003 端口是否被 PhpStorm 占用:
1 | netstat -ano | findstr 9003 |
若输出以下内容(LISTENING 状态),说明侦听正常:
1 | TCP 0.0.0.0:9003 0.0.0.0:0 LISTENING 31268 # 31268 是 PhpStorm 进程 ID |
以 Hyperf 项目为例,在 WSL 中启动项目,然后验证 PhpStorm 与 WSL 的连接。
进入项目根目录,执行启动命令(不同框架命令不同):
1 | # Hyperf 项目启动命令 |
启动成功后输出:
1 | [INFO] Worker#0 started. |
再次执行端口监听命令,查看是否出现「ESTABLISHED」状态(表示 WSL 与 PhpStorm 已建立连接):
1 | netstat -ano | findstr 9003 |
成功连接的输出:
1 | TCP 0.0.0.0:9003 0.0.0.0:0 LISTENING 31268 |
连接成功后,即可通过断点调试查看变量、调用栈等信息,以 Hyperf 控制器为例:
app/Controller/IndexController.php,在 index 方法的第一行代码左侧点击,出现红色圆点(断点)。http://127.0.0.1:9501(Hyperf 默认接口),或用 Postman 发送请求。F8:单步执行(跳过函数内部)。F7:单步进入(进入函数内部)。Shift + F8:单步跳出(从函数内部跳出)。F9:继续执行(直到下一个断点)。\,WSL 路径带 /)。php -i | grep XDebug,确认 xdebug.mode 包含 debug,xdebug.client_host 为 host.docker.internal。netstat -ano | findstr 9003 查看是否有其他进程占用 9003 端口,若有则修改 xdebug.client_port 为其他端口(如 9004),并同步更新 PhpStorm 配置。xdebug.client_host 为 Windows 的局域网 IP,如 192.168.1.100)。xdebug.log=/var/log/xdebug.log,查看日志中的错误信息(如 Could not connect to client host)。php -v 不显示 XDebug 信息 → 确保安装的 XDebug 包与 PHP 版本匹配(PHP 8.1 对应 php81-pecl-xdebug,PHP 8.2 对应 php82-pecl-xdebug)。通过以上步骤,即可在 Windows 11 + WSL2(Alpine)环境下实现 PhpStorm 与 XDebug 的无缝调试。核心是「版本匹配」「路径映射」「端口一致」三个关键点,遇到问题时优先查看 XDebug 日志和端口监听状态,大部分问题可快速定位解决。
Superfetch,直译为 “超级预取” ,是 Windows 系统中的一项智能服务,最早在 Windows Vista 系统中引入,后续的 Windows 7、Windows 8 以及 Windows 10 等系统版本也都沿用了这一功能,其核心作用在于提升系统和应用程序的运行速度。
它的运行原理基于对用户使用习惯的深度学习与分析。当我们日常使用电脑时,Superfetch 会在后台默默监控我们频繁开启的各类程序。一旦它 “熟悉” 了我们的使用模式,就会将这些常用程序运行时所依赖的数据和代码,提前加载到内存之中。就好比你每天早上出门前,会提前把当天要用的文件准备好放在包里,等真正需要的时候,就能迅速拿出来使用,无需再临时翻找。
举个简单的例子,假如你每天上班打开电脑后的第一件事就是启动微信与同事沟通工作,那么 Superfetch 服务就会 “记住” 这个习惯。在你下次开机时,它会提前将微信运行所需的关键文件和数据从硬盘读取到内存里。这样一来,当你点击微信图标时,程序便能从内存中快速获取所需内容,实现几乎瞬间启动,大大节省了等待时间,让你的工作衔接更加顺畅高效。又或者你经常使用 Photoshop 处理图片,Superfetch 也会将 Photoshop 运行时可能用到的图像算法库、常用滤镜数据等提前加载,使得你在启动 Photoshop 以及使用各种功能时,响应速度明显加快,创作过程更加流畅。
不过,Superfetch 在发挥作用的过程中,也会对系统资源产生一定的占用。它需要消耗一定的 CPU 运算资源来分析用户行为模式,同时还会占用一部分内存空间用于存放预读取的数据,这也是我们在考虑是否禁用它时需要权衡的因素。
尽管 Superfetch 服务出发点是好的,旨在提升系统性能,但在实际使用中,不少用户却萌生出禁用它的想法,这背后有着多方面的原因。
Superfetch 服务在运行过程中,对系统资源有着较高的需求。它需要持续分析用户的使用习惯,这一过程会占用一定的 CPU 资源,尤其是在系统刚刚启动或者用户使用习惯发生较大变化时,CPU 的占用率会明显上升,导致电脑在这段时间内反应迟缓,打开其他程序时也会出现卡顿现象。比如,当你早上开机后,想要快速打开多个办公软件开始一天的工作,却发现电脑变得异常迟钝,很可能就是 Superfetch 服务在后台大量占用 CPU 资源,使得其他程序无法及时获取足够的运算资源来启动。
同时,Superfetch 会将预读取的数据存储在内存中,这无疑会占用相当一部分内存空间。对于那些内存容量本身就不大的电脑来说,这可能会导致系统内存紧张。当内存不足时,系统会频繁地进行内存与硬盘之间的数据交换,也就是我们常说的 “虚拟内存” 操作,这会大大降低系统的运行效率,使电脑整体变得卡顿,严重影响用户体验。
在固态硬盘(SSD)普及之前,Superfetch 服务对于提升机械硬盘的读取速度效果显著。因为机械硬盘的读写速度相对较慢,通过预读取数据到内存,可以有效减少等待时间。然而,随着 SSD 的广泛应用,情况发生了变化。SSD 采用闪存芯片作为存储介质,其随机读写速度比机械硬盘快了数倍甚至数十倍,能够在极短的时间内读取大量数据。在这种情况下,Superfetch 服务提前预取数据的优势就不再那么明显,其对系统性能的提升效果变得微乎其微。许多用户发现,即使禁用了 Superfetch 服务,使用 SSD 的电脑在程序启动速度和系统响应速度上依然表现出色,并没有因为缺少了 Superfetch 的预取功能而受到明显影响。
有时候,Superfetch 服务可能会出现异常情况,导致硬盘占用率居高不下。这是因为它在预取数据时,可能会频繁地对硬盘进行读写操作。当硬盘的读写任务过于繁重时,就会出现 100% 占用的情况,此时电脑会变得异常卡顿,几乎无法进行正常操作。比如,你正在使用电脑进行视频剪辑或者玩大型游戏,突然发现电脑变得反应迟缓,打开文件或者切换程序都要等待很长时间,查看任务管理器后发现硬盘占用率达到了 100%,而罪魁祸首很可能就是 Superfetch 服务。这种异常情况不仅会影响当前正在进行的工作和娱乐,还可能对硬盘的寿命产生一定的影响。
不同版本的 Windows 系统,禁用 Superfetch 服务的方法略有差异,下面分别为大家介绍 Windows 7、Windows 10 和 Windows 11 系统下的具体操作步骤。
打开服务管理器:同时按下键盘上的Win + R组合键,调出 “运行” 对话框,在对话框中输入services.msc,然后按下回车键Enter,即可打开服务管理器窗口。
找到 Superfetch 服务:在服务管理器窗口中,会显示出众多系统服务,这些服务按照字母顺序排列。我们需要在列表中仔细查找名为 “Superfetch” 的服务。
停止 Superfetch 服务:找到 “Superfetch” 服务后,双击该服务,打开其属性窗口。在属性窗口的 “常规” 标签页中,将 “启动类型” 从原来的 “自动” 设置为 “已禁用”。设置完成后,点击 “停止” 按钮,此时 Superfetch 服务就会停止运行。
保存设置:点击 “确定” 按钮,保存我们所做的更改设置。这样,在下次系统启动时,Superfetch 服务就不会自动运行了。
打开计算机管理:在 Windows 10 桌面,右键点击 “此电脑” 图标,在弹出的菜单中选择 “管理” 菜单项,即可打开计算机管理窗口。
进入服务选项:在打开的计算机管理窗口中,点击左侧列表中的 “服务和应用程序” 一项,展开该项后,再点击 “服务” 菜单项 ,此时在窗口右侧会显示出所有的系统服务列表。
找到并设置 Superfetch 服务:在服务列表中找到 “superfetch” 一项,双击它打开 “superfetch” 的属性窗口。首先点击 “停止” 按钮,关闭当前正在运行的 superfetch 服务。然后为了防止下次开机时该服务自动启动,点击 “启动类型” 下拉菜单,在弹出的菜单中选择 “禁用” 菜单项。
确认保存:完成上述设置后,点击 “确定” 按钮保存设置,关闭属性窗口即可。
使用服务应用程序:按下Windows+S组合键启动 “搜索” 菜单,在顶部的文本字段中输入 “服务”,然后单击相关搜索结果。在打开的服务窗口中找到 “SysMain” 条目(在 Windows 11 中 Superfetch 服务改名为 SysMain ),右键单击它,然后从上下文菜单中选择 “属性”,或者直接双击该服务。在弹出的属性窗口中,单击 “启动类型” 下拉菜单,然后从选项列表中选择 “禁用”。接下来,如果当前服务正在运行,请单击 “服务状态” 下的 “停止” 按钮,最后单击底部的 “确定” 以保存更改。完成后重新启动计算机,以使更改生效。
使用命令提示符:按下Windows+S组合键启动搜索菜单,在文本字段中输入 “终端”,右键单击相关搜索结果,然后从上下文菜单中选择 “以管理员身份运行”。在弹出的用户帐户控制(UAC)提示中单击 “是”。单击顶部的向下箭头,然后选择 “Command Prompt”(命令提示符)。或者,也可以按下Ctrl+Shift+2组合键在新选项卡中启动命令提示符。在命令提示符窗口中,粘贴以下命令并点击Enter键停止服务:net.exe stop sysmain。接着,执行以下命令以禁用 Superfetch 在启动时加载:sc config sysmain start=disabled。
使用注册表编辑器:按下Windows+R组合键启动运行命令,在文本字段中输入regedit,然后单击 “确定” 或点击Enter键启动注册表编辑器。在弹出的 UAC 提示中单击 “是”。在注册表编辑器中,将以下路径粘贴到顶部的地址栏中,然后点击Enter键,或者也可以使用左侧的导航窗格依次展开路径:Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PrefetchParameters。在该路径下,右键单击空白区域,将光标悬停在 “新建” 上,然后从上下文菜单中选择 “DWORD(32 位)值”。将该条目命名为 “EnableSuperfetch”,然后双击它以修改属性。在 “数值数据” 下的文本字段中输入 “0” ,然后单击 “确定” 以保存更改。进行更改后,重新启动计算机以使更改生效。不过使用注册表编辑器时需格外小心,错误的修改可能会导致系统出现严重问题。
禁用 Superfetch 服务,犹如在电脑的系统生态中做出一次关键的 “调整”,这一操作会带来多方面的影响,既可能有性能提升的惊喜,也可能伴随着一些负面效应,需要我们全面客观地去看待。
释放系统资源:正如前文所提到的,Superfetch 服务在运行时会占用一定的 CPU 和内存资源。当我们禁用它后,这些被占用的资源将被释放出来,可供其他程序使用。对于那些配置相对较低的电脑而言,这无疑是个好消息。例如,一台只有 4GB 内存的笔记本电脑,在禁用 Superfetch 服务后,原本被其占用的几百 MB 内存得以释放,电脑在运行多个程序时,内存不再那么紧张,程序之间的切换也变得更加流畅,不容易出现因内存不足而导致的卡顿现象。
减少硬盘读写:Superfetch 服务为了实现预取功能,会频繁地对硬盘进行读写操作。尤其是在系统启动和程序运行初期,这种读写操作更为明显。禁用该服务后,硬盘的读写负担将大大减轻。对于使用机械硬盘的电脑来说,这可以有效减少硬盘的磨损,延长硬盘的使用寿命;而对于固态硬盘,虽然其读写速度快,但减少不必要的读写操作也有助于降低固态硬盘的写入放大效应,从而延长其寿命,同时也能减少因硬盘读写而产生的热量。
特定场景下的性能提升:在某些特定场景中,禁用 Superfetch 服务能够显著提升系统性能。比如,对于一些追求极致游戏性能的玩家来说,在玩大型游戏时,禁用 Superfetch 服务可以避免其在后台占用资源,使游戏能够获得更多的系统资源,从而提升游戏的帧率和稳定性,减少游戏过程中的卡顿现象,让玩家能够更加流畅地享受游戏带来的乐趣。又或者对于从事视频剪辑、3D 建模等对系统性能要求较高的专业用户来说,禁用 Superfetch 服务后,他们在使用这些专业软件时,软件的响应速度会更快,操作更加流畅,能够大大提高工作效率。
系统启动和程序加载变慢:Superfetch 服务的核心作用是提前预取系统和程序运行所需的数据,从而加快系统启动和程序加载速度。一旦禁用它,系统在启动时就无法提前将常用程序的数据加载到内存中,程序在启动时也需要从硬盘中实时读取数据,这必然会导致系统启动时间变长,程序的首次加载速度明显变慢。例如,原本开机后几秒钟就能快速启动的微信,在禁用 Superfetch 服务后,可能需要等待十几秒甚至更长时间才能打开,这对于那些追求高效、希望能够快速进入工作或娱乐状态的用户来说,无疑是一种困扰。
内存管理可能受影响:Superfetch 服务在一定程度上参与了系统的内存管理,它通过分析用户的使用习惯,合理地将数据预加载到内存中,使得内存的使用更加高效。当禁用该服务后,系统的内存管理可能会受到一定影响。内存中可能无法及时存放常用程序的数据,导致程序在运行过程中频繁地进行内存与硬盘之间的数据交换,增加了系统的负担,进而可能影响到系统的整体性能和稳定性,使电脑在运行多个程序时容易出现卡顿现象。
影响用户体验:从整体用户体验的角度来看,禁用 Superfetch 服务带来的启动和加载变慢问题,可能会让用户在日常使用电脑的过程中感到烦躁和不便。尤其是在当今快节奏的生活和工作环境下,时间的碎片化使得用户希望每一次使用电脑都能够快速、高效地完成任务,而这种等待时间的增加无疑与用户的期望背道而驰,可能会降低用户对电脑使用的满意度 。
禁用 Superfetch 服务并非适用于所有用户和所有电脑,在决定是否禁用之前,我们需要综合多方面因素进行判断,找到最适合自己电脑的设置方案 。
低配置电脑:如果你的电脑配置较低,例如 CPU 性能较弱、内存容量较小(4GB 及以下),且使用的是机械硬盘,那么禁用 Superfetch 服务可能会为你带来一定的性能提升。因为这类电脑本身资源有限,Superfetch 服务占用的资源可能会对其他程序的运行产生较大影响。禁用它后,可以释放出更多的系统资源,让电脑运行更加流畅。
高配置电脑:对于高配置电脑,如配备高性能 CPU、大容量内存(16GB 及以上)以及快速的固态硬盘,Superfetch 服务所占用的资源相对来说对系统整体性能的影响较小。在这种情况下,保留 Superfetch 服务可能会使系统和程序的启动速度更快,用户体验更好,因此不一定需要禁用它。
固定使用场景:如果你每天使用电脑的场景比较固定,总是运行相同的几个程序,那么 Superfetch 服务能够很好地发挥其预取作用,提前加载常用程序,减少等待时间。这种情况下,保留该服务会更符合你的使用需求。比如,你是一名上班族,每天主要使用办公软件(Word、Excel、PPT)、通讯工具(微信、QQ)以及浏览器进行工作,Superfetch 服务能够根据你的使用习惯,提前将这些程序所需的数据加载到内存中,让你能够快速进入工作状态。
频繁切换使用场景:然而,如果你经常在不同的使用场景之间切换,运行各种不同类型的程序,Superfetch 服务可能无法及时准确地预取到你需要的数据。因为它需要一定的时间来分析你的新使用习惯并进行预取,在这种频繁变化的情况下,其预取效果可能并不理想,此时禁用它可能不会对你的使用造成太大影响。
系统卡顿明显:如果你在日常使用电脑的过程中,经常遇到系统卡顿、反应迟缓的情况,并且通过任务管理器等工具发现 Superfetch 服务占用了大量的 CPU、内存或硬盘资源,那么可以尝试禁用该服务,观察系统性能是否有所改善。例如,在打开多个程序时,电脑出现长时间无响应,查看任务管理器发现 Superfetch 服务占用了较高的 CPU 资源,此时禁用它可能会使系统恢复流畅。
系统运行流畅:相反,如果你的电脑在运行过程中一直表现得很流畅,系统和程序的启动速度也能满足你的需求,那么就没有必要冒险去禁用 Superfetch 服务,以免带来不必要的负面影响。
禁用 Superfetch 服务,是一把双刃剑,有着明显的利弊两面。从积极的方面来看,它能够释放系统资源,减少对 CPU、内存和硬盘的占用,尤其对于低配置电脑以及机械硬盘,在一定程度上可提升系统运行的流畅度,降低硬盘的读写负担,延长硬盘使用寿命。同时,在特定的使用场景下,比如追求极致游戏性能或专业软件运行效率时,能让电脑将更多资源集中于关键任务,带来更好的性能表现。
然而,我们也不能忽视其负面效应。禁用 Superfetch 服务后,系统启动和程序加载速度会明显变慢,这会在日常使用中增加等待时间,降低工作和娱乐的效率。而且,它还可能影响系统的内存管理机制,导致内存使用不够合理,进而影响系统的整体稳定性和性能。
对于不同用户群体,建议如下:如果你的电脑配置较低,且使用场景较为单一,日常主要运行少数几个固定程序,那么可以尝试禁用 Superfetch 服务,通过释放系统资源来提升电脑的运行流畅度。但在操作之前,务必备份好重要数据,以防万一。
而对于高配置电脑用户,若电脑在运行过程中没有出现明显的资源不足或卡顿问题,保留 Superfetch 服务通常能获得更便捷、高效的使用体验,因为它可以让系统和程序的启动更加迅速。
总之,是否禁用 Superfetch 服务,需要我们根据自身电脑的实际配置、使用习惯以及系统性能表现等多方面因素,进行全面、谨慎的考虑和权衡。在操作过程中,一定要谨慎行事,尤其是涉及到修改系统服务和注册表等关键设置时,以免因不当操作导致系统出现严重问题,影响正常使用。
在 Alpine Linux 环境中使用 PhpStorm 的 Git 工具时,部分开发者可能会遇到以下错误提示,导致版本控制功能无法正常使用。本文将详细分析问题成因并提供分步解决方案。
当尝试在 PhpStorm 中更新代码或执行 Git 操作时,控制台会抛出以下异常:
1 | Error updating changes: setsid: unrecognized option: w |

关键问题点:BusyBox 提供的 setsid 命令不支持-w选项,而 PhpStorm 的 Git 工具可能默认调用了该参数,导致命令执行失败。
Alpine Linux 默认使用 BusyBox 工具集,其内置的setsid命令仅支持-c选项(设置控制终端),但 PhpStorm 等 IDE 的 Git 插件可能依赖 GNU Core Utilities 中的setsid命令(支持更多选项,如-w)。由于 BusyBox 的setsid与 GNU 版本存在兼容性差异,导致 IDE 调用时参数不匹配。
以下操作需在终端中以管理员权限(sudo)执行,逐步修复命令冲突问题:
1 | cd /usr/bin/ |

setsid实际指向 BusyBox 的busybox二进制文件(通过软链接setsid2)。1 | mv setsid setsid2 |
setsid与后续安装的 GNU 版本冲突。Alpine 默认仓库中的coreutils包提供 GNU 版本的工具集,执行以下命令安装并复制setsid:
下载地址:setsid
1 | cp setsid /usr/bin/setsid |
注意:若coreutils安装后setsid路径不同(如/usr/bin/setsid已存在),请根据实际路径调整拷贝命令。
1 | chmod 777 /usr/bin/setsid |

setsid: unrecognized option: w错误,则说明修复成功。setsid -w echo test,若正常输出test且无报错,表明 GNU 版本的setsid已生效。setsid为 GNU 版本,解决 IDE 参数调用不兼容问题。setsid2到其他目录)。coreutils并替换对应命令解决。通过以上步骤,即可在 Alpine 系统中恢复 PhpStorm 的 Git 工具正常使用,确保开发流程不受环境差异影响。
递归公用表表达式(Recursive CTE)是 MySQL 8.0 引入的高级特性,通过WITH RECURSIVE语法定义,允许在 CTE 内部递归引用自身,专门用于处理具有层级关系的树形数据,如组织架构、分类目录、文件系统等。其核心思想是通过锚成员(初始查询)和递归成员(迭代查询)的结合,逐层扩展结果集,直至满足终止条件(递归成员返回空集)。
组织架构管理:查询某个部门的所有上下级节点。
分类目录遍历:获取商品分类的全层级路径。
树状结构分析:查找节点的所有祖先或后代,替代传统自连接或存储过程的复杂逻辑。
1 | WITH RECURSIVE cte_name (column_list) AS ( |
锚成员执行:生成初始结果集(R0),如指定节点的基础信息。
递归迭代:将上一次结果集(Ri)作为输入,通过UNION ALL合并新生成的结果集(Ri+1),直到递归成员返回空集。
终止条件:隐式终止于递归成员无数据返回,或显式通过条件(如WHERE n < 100)限制递归深度。
禁止使用聚合函数(如SUM/COUNT)、GROUP BY、ORDER BY、LIMIT、DISTINCT(UNION DISTINCT除外)。
仅能引用 CTE 名称,不能嵌套子查询。
场景:从子节点出发,逐层查找所有上级节点(如员工查询其所有管理层级)。表结构:club(id, name, pid),pid为父节点 ID,根节点pid为NULL。SQL 示例:
1 | WITH RECURSIVE parent_path AS ( |
解析:从 id=5 开始,每次递归通过pid找到父节点,直至无更高层级节点。
场景:从父节点出发,获取其所有直接及间接子节点(如部门主管查询下属团队)。SQL 示例:
1 | WITH RECURSIVE child_path AS ( |
解析:以 id=3 为起点,逐层匹配pid=当前id的子节点,实现无限层级遍历。
场景:在查询结果中显式节点层级,方便分页或排序(如目录树展示)。SQL 示例:
1 | WITH RECURSIVE level_tree AS ( |
解析:通过level字段量化层级深度,避免表设计时预存层级的冗余问题。
场景:传统 Java/Python 代码中,递归遍历组织架构易导致性能瓶颈,改用递归 CTE 后可在数据库层高效完成。MyBatis 映射示例:
1 | WITH RECURSIVE DeptTree AS ( |
优势:避免多次往返数据库,单条 SQL 完成层级查询,提升系统响应速度。
仅支持 MySQL 8.0 及以上版本,低版本需使用存储过程或应用层递归实现。
数据校验:确保层级数据无环(如 A→B→A),否则递归会因无法终止报错(默认最大递归深度 1000,可通过SET @@cte_max_recursion_depth = N调整)。
条件限制:在递归成员中添加合理过滤条件(如WHERE level < 50),防止无限递归。
为id和pid字段添加索引,提升递归过程中 JOIN 操作的效率,尤其对大规模层级数据至关重要。
若数据存在重复关联,可在最终查询中使用DISTINCT去重,但需注意递归成员中禁止直接使用DISTINCT。
递归 CTE 是 MySQL 处理树形数据的 “瑞士军刀”,通过简洁的语法将复杂的层级查询转化为结构化的递归过程,显著提升开发效率与查询性能。无论是组织架构、分类目录还是其他层级场景,掌握递归 CTE 的锚成员定义、递归规则设计及终止条件把控,都能让你在数据处理中游刃有余。建议在实际项目中结合索引优化与数据校验,充分发挥其在层级查询中的优势。
动手实践:尝试在示例表club中插入多级数据,分别编写查询根节点、叶节点及全路径的递归 CTE 语句,观察结果差异与执行效率。