Burp Suite 中文乱码解决
在使用 Burp Suite 进行 HTTP 请求或响应分析时,可能遇到请求参数、响应内容中的中文显示为乱码的情况,例如显示为乱码符号(如方框、问号等),影响数据查看和分析。
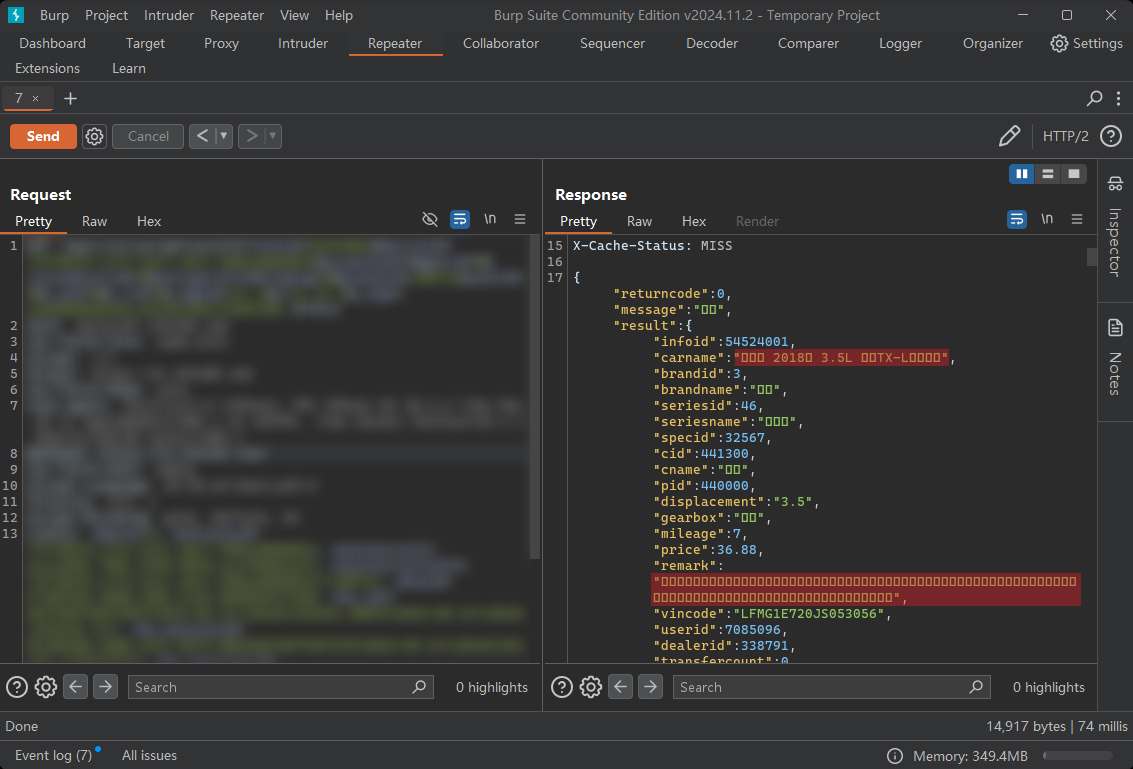
Burp Suite 默认的字符编码或字体设置与中文不兼容,导致无法正确解析和显示中文字符。常见原因包括:
编码格式错误:未设置为 UTF-8(中文通用编码)。
字体不支持中文:默认字体无法渲染中文字符。
解决步骤
进入设置页面
打开 Burp Suite,点击顶部菜单栏的 Settings(设置),选择 User Interface(用户界面)。
修改消息编辑器的编码和字体
在左侧导航栏中选择 Message editor(消息编辑器)。
在右侧的 Character sets(字符编码)下拉菜单中,选择 UTF-8(确保与目标网站的编码一致)。
更换支持中文的字体:在 Font(字体)选项中,点击 Change font(选择字体),从列表中选择支持中文的字体(如 Microsoft YaHei、SimSun 或 黑体),调整字体大小至合适显示。
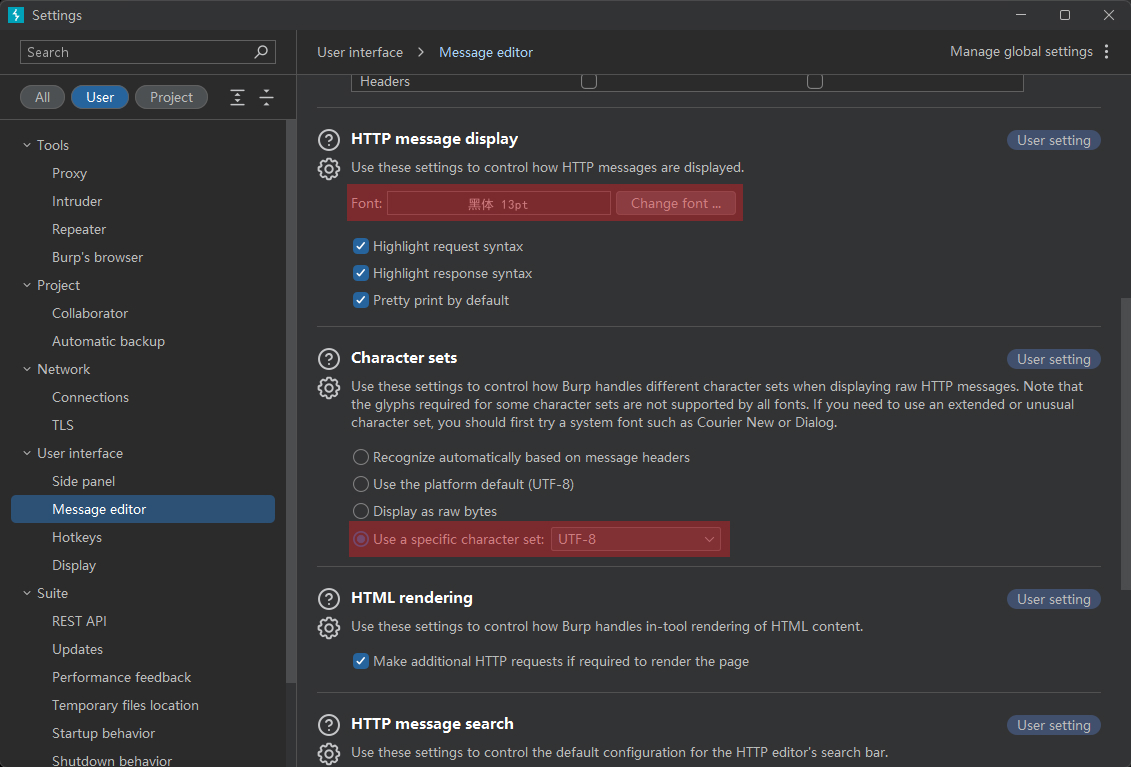
修改完成后,就可以正常查看中文字体了
Python自动化神器PyAutoGUI,效率飙升不是梦!
PyAutoGUI 是什么
在 Python 的自动化领域中,PyAutoGUI 是一个非常实用的库,它允许我们通过编写代码来模拟鼠标和键盘的操作,从而实现自动化任务 。无论是重复性的日常工作,还是复杂的软件测试流程,PyAutoGUI 都能发挥重要作用,帮助我们节省时间和精力。
想象一下,你需要在某个软件中重复进行一系列的点击、输入操作,要是手动完成,不仅耗时,还容易出错。但有了 PyAutoGUI,你只需编写一个简单的 Python 脚本,就能让计算机自动执行这些任务。比如自动填写表格、批量处理文件、自动化测试软件功能等,这些操作都能轻松实现。
PyAutoGUI 的安装
在开始使用 PyAutoGUI 之前,我们需要先将其安装到我们的 Python 环境中。安装 PyAutoGUI 非常简单,使用 pip 命令即可完成 。打开你的命令行工具,输入以下命令:
1 | pip install pyautogui |
如果你使用的是 Python 3.9 或更高版本,也可以使用pip3命令进行安装:
1 | pip3 install pyautogui |
安装过程中,pip 会自动下载 PyAutoGUI 及其依赖项 。等待安装完成后,你就可以在 Python 脚本中导入并使用 PyAutoGUI 了。
需要注意的是,在安装之前,请确保你的 Python 环境已经正确配置,并且 pip 已经安装在系统上。如果你在 Windows 操作系统上使用 Python,还要确保已将 Python 添加到系统的环境变量中,以便能够在命令提示符中运行 pip。 如果你在安装过程中遇到问题,可以参考 PyAutoGUI 的官方文档,或者在相关技术论坛上寻求帮助。
PyAutoGUI 的强大功能展示
鼠标操作
1. 移动鼠标
在 PyAutoGUI 中,控制鼠标移动主要通过moveTo()和moveRel()函数 。moveTo()函数用于将鼠标移动到屏幕上的指定坐标位置,它的语法如下:
1 | pyautogui.moveTo(x, y, duration=0) |
其中,x和y是目标坐标的横坐标和纵坐标,duration是可选参数,表示鼠标移动到目标位置所需的时间,单位为秒。如果不设置duration,鼠标会瞬间移动到指定位置。例如,要将鼠标移动到屏幕坐标为 (500, 300) 的位置,可以使用以下代码:
1 | import pyautogui |
moveRel()函数则是相对于当前鼠标位置进行移动,语法为:
1 | pyautogui.moveRel(xOffset, yOffset, duration=0) |
xOffset和yOffset分别是水平和垂直方向上的偏移量,正数表示向右和向下移动,负数表示向左和向上移动。同样,duration是移动所需的时间。比如,要让鼠标在当前位置的基础上向右移动 100 个像素,向下移动 50 个像素,可以这样写:
1 | import pyautogui |
2. 点击操作
PyAutoGUI 提供了多个函数来实现鼠标的点击操作,包括click()、doubleClick()、rightClick()和middleClick()等 。click()函数是最常用的点击函数,它可以模拟鼠标的左键点击、右键点击以及中键点击,还可以设置点击的次数和间隔时间。语法如下:
1 | pyautogui.click(x=None, y=None, clicks=1, interval=0.0, button='left') |
x和y是点击的坐标位置,如果不指定则在当前鼠标位置点击;clicks表示点击的次数,默认为 1 次;interval是每次点击之间的间隔时间,单位为秒;button指定点击的鼠标按钮,可选值为 ‘left’。例如,要在坐标 (400, 200) 处进行两次左键点击,每次点击间隔 0.5 秒,可以使用以下代码:
1 | import pyautogui |
doubleClick()函数专门用于模拟鼠标左键的双击操作,语法为:
1 | pyautogui.doubleClick(x=None, y=None, interval=0.0) |
x和y是双击的坐标位置,interval是两次点击之间的间隔时间。例如:
1 | import pyautogui |
rightClick()和middleClick()函数分别用于模拟鼠标右键点击和中键点击,语法类似,只需在调用时传入相应的坐标位置即可。例如:
1 | import pyautogui |
3. 鼠标拖拽
实现鼠标拖拽操作的函数是dragTo()和dragRel() 。dragTo()函数将鼠标从当前位置拖动到指定的坐标位置,语法如下:
1 | pyautogui.dragTo(x, y, duration=0, button='left') |
x和y是目标坐标,duration是拖动所需的时间,button指定拖动时使用的鼠标按钮,默认为左键。比如,要将鼠标从当前位置拖动到坐标 (600, 400) 处,耗时 3 秒,可以使用以下代码:
1 | import pyautogui |
dragRel()函数则是相对于当前鼠标位置进行拖动,语法为:
1 | pyautogui.dragRel(xOffset, yOffset, duration=0, button='left') |
xOffset和yOffset是水平和垂直方向上的偏移量,duration是拖动时间,button是鼠标按钮。例如,要让鼠标在当前位置的基础上,向右拖动 80 个像素,向上拖动 30 个像素,耗时 2 秒,可以这样写:
1 | import pyautogui |
4. 鼠标滚动
控制鼠标滚轮滚动的函数是scroll(),语法如下:
1 | pyautogui.scroll(clicks) |
clicks是一个整数参数,表示滚动的距离,正数表示向上滚动,负数表示向下滚动。例如,要让鼠标滚轮向上滚动 5 个单位,可以使用以下代码:
1 | import pyautogui |
如果要向下滚动 10 个单位,则可以这样写:
1 | import pyautogui |
键盘操作
1. 按键模拟
在 PyAutoGUI 中,模拟按键按下和释放主要使用press()、keyDown()和keyUp()函数 。press()函数用于模拟按下并释放一个按键,语法如下:
1 | pyautogui.press(key) |
key是要按下的按键名称,可以是单个字符,如 ‘a’、’b’,也可以是特殊按键,如 ‘enter’等。例如,要模拟按下回车键,可以使用以下代码:
1 | import pyautogui |
keyDown()函数用于模拟按下一个按键,而不释放,语法为:
1 | pyautogui.keyDown(key) |
keyUp()函数则用于模拟释放一个按键,语法为:
1 | pyautogui.keyUp(key) |
这两个函数通常一起使用,以实现对按键的精确控制。例如,要模拟按住 Shift 键的同时按下 ‘a’ 键,然后释放 Shift 键,可以这样写:
1 | import pyautogui |
2. 文本输入
实现自动化文本输入的函数是typewrite(),语法如下:
1 | pyautogui.typewrite(message, interval=0.0) |
message是要输入的文本内容,可以是字符串;interval是可选参数,表示输入每个字符之间的时间间隔,单位为秒。例如,要在当前光标位置输入 “Hello, World!”,每个字符之间间隔 0.2 秒,可以使用以下代码:
1 | import pyautogui |
如果要输入包含特殊按键的组合,比如先按 ‘enter’ 键,再输入 “Python”,可以将按键和文本内容放在一个列表中传递给typewrite()函数,例如:
1 | import pyautogui |
3. 组合键操作
模拟组合键操作可以使用hotkey()函数,语法如下:
1 | pyautogui.hotkey(*keys) |
keys是要组合的按键名称,可以传递多个参数。例如,要模拟按下 Ctrl+C 组合键,可以使用以下代码:
1 | import pyautogui |
同样,要模拟按下 Alt+Tab 组合键,可以这样写:
1 | import pyautogui |
屏幕操作
1. 屏幕截图
获取屏幕截图的函数是screenshot(),它可以返回一个表示屏幕截图的 Pillow 图像对象 。语法如下:
1 | im = pyautogui.screenshot() |
im就是返回的图像对象,你可以对其进行保存、分析等操作。例如,要将屏幕截图保存为名为 “screenshot.png” 的文件,可以使用以下代码:
1 | import pyautogui |
如果你只想截取屏幕的某个区域,可以使用region参数指定截取区域的左上角坐标和宽度、高度,语法如下:
1 | im = pyautogui.screenshot(region=(left, top, width, height)) |
left和top是截取区域左上角的横坐标和纵坐标,width和height是截取区域的宽度和高度。例如,要截取屏幕左上角坐标为 (100, 100),宽度为 200,高度为 150 的区域,可以这样写:
1 | import pyautogui |
2. 图像识别定位
在屏幕上查找指定图像位置的函数主要有locateOnScreen()和locateCenterOnScreen() 。locateOnScreen()函数用于在屏幕上查找指定图像的位置,并返回其边界框的坐标,语法如下:
1 | location = pyautogui.locateOnScreen(image, grayscale=False, confidence=None) |
image是要查找的图像文件名或 Pillow 图像对象;grayscale是可选参数,设置为True时会以灰度模式查找图像,这样可以提高查找速度,但可能会降低准确性;confidence是可选参数,表示匹配的置信度,取值范围为 0 到 1,值越高表示匹配要求越严格,默认值为None,即不进行置信度匹配。location返回一个包含边界框坐标的四元组(left, top, width, height),如果未找到图像,则返回None。例如,要在屏幕上查找名为 “button.png” 的图像位置,可以使用以下代码:
1 | import pyautogui |
locateCenterOnScreen()函数则是在屏幕上查找指定图像的位置,并返回其中心点的坐标,语法如下:
1 | center = pyautogui.locateCenterOnScreen(image, grayscale=False, confidence=None) |
center返回一个包含中心点坐标的二元组(x, y),如果未找到图像,则返回None。例如:
1 | import pyautogui |
这些屏幕操作函数结合鼠标和键盘操作函数,可以实现更加复杂的自动化任务,比如根据屏幕上的图像位置进行点击、输入等操作。
实战应用案例
自动化测试
假设我们正在开发一款简单的图形界面应用程序,其中有一个登录窗口,包含用户名输入框、密码输入框和登录按钮 。我们可以使用 PyAutoGUI 编写自动化测试脚本来模拟用户登录操作,检查应用程序的登录功能是否正常。以下是一个简单的示例代码:
1 | import pyautogui |
在这个示例中,我们首先通过locateCenterOnScreen函数查找应用程序图标、用户名输入框、密码输入框和登录按钮的位置,然后使用click和typewrite函数模拟用户的点击和输入操作 。最后,通过查找登录成功后的提示框来判断登录是否成功。这样,我们就可以自动化地对应用程序的登录功能进行多次测试,大大提高了测试效率和准确性。
数据采集与处理
比如,我们需要从一个电商网站上采集商品信息,包括商品名称、价格、销量等 。我们可以使用 PyAutoGUI 结合一些图像识别和文本处理技术来实现自动化采集。以下是一个简单的思路和示例代码:
1 | import pyautogui |
在这个示例中,我们首先打开浏览器并访问电商网站,然后模拟搜索商品 。接着,通过截取屏幕上商品信息区域的截图,并使用 OCR 技术识别截图中的文本,从而提取出商品的相关信息。最后,通过模拟点击下一页按钮,实现多页商品信息的采集。
软件演示与教程录制
假设我们要制作一个关于某个绘图软件使用教程的视频,我们可以使用 PyAutoGUI 自动化演示软件的各种功能,并配合录屏软件进行录制 。以下是一个简单的示例代码,展示如何使用 PyAutoGUI 打开绘图软件并进行一些基本操作:
1 | import pyautogui |
在这个示例中,我们首先通过图像识别找到绘图软件的图标并打开软件 。然后,找到矩形绘制工具并使用鼠标操作绘制一个矩形。最后,演示保存绘制图形的操作。在运行这段代码时,同时开启录屏软件,就可以录制出一个完整的软件使用教程视频,大大提高了制作教程的效率和准确性。
游戏辅助工具
以简单的扫雷游戏为例,我们可以使用 PyAutoGUI 制作一个辅助工具,帮助玩家自动识别雷区和点击安全区域 。以下是一个简单的实现思路和示例代码:
1 | import pyautogui |
在这个示例中,我们首先定义了雷区格子的大小和初始位置,然后加载数字图片模板用于识别雷区中的数字 。recognize_number函数通过模板匹配的方式识别每个格子中的数字,analyze_minefield函数则对整个雷区进行截图并分析每个格子的数字。通过这种方式,我们可以根据识别出的数字来判断哪些区域是安全的,哪些区域可能有雷,从而实现简单的扫雷游戏辅助功能。 请注意,在实际游戏中使用辅助工具可能涉及违反游戏规则的问题,仅用于技术学习和研究目的。
使用注意事项与技巧
防故障机制
PyAutoGUI 提供了自动防故障功能,默认情况下是开启的 。当鼠标移动到屏幕的左上角时,会触发FailSafeException异常,程序会停止执行,这可以防止程序出现异常情况时无法停止,导致不可预期的后果 。如果你确定自己的程序不会出现问题,或者在调试过程中不想被这个机制中断,可以通过以下方式禁用它:
1 | import pyautogui |
不过,禁用故障保护可能会带来风险,因此请谨慎操作。 另外,为了避免操作速度过快导致程序出错或错过某些界面元素的响应,你可以设置停顿功能 。通过设置pyautogui.PAUSE变量,可以让每个 PyAutoGUI 函数调用在执行动作后暂停指定的秒数。例如,设置暂停时间为 1 秒:
1 | import pyautogui |
这样,在执行诸如鼠标移动、点击、键盘输入等操作后,程序都会暂停 1 秒,给系统和其他应用程序足够的时间来响应。
坐标定位技巧
在使用 PyAutoGUI 进行鼠标操作时,准确获取屏幕坐标非常关键 。你可以使用pyautogui.position()函数来获取当前鼠标的坐标位置,返回一个包含横坐标和纵坐标的元组 。例如:
1 | import pyautogui |
另外,在进行图像识别定位时,为了提高定位的准确性和稳定性,可以设置locateOnScreen()函数的confidence参数 。该参数表示匹配的置信度,取值范围为 0 到 1,值越高表示匹配要求越严格 。例如,将置信度设置为 0.8:
1 | import pyautogui |
当在不同分辨率的屏幕上运行自动化脚本时,由于相同的像素坐标在不同分辨率下代表的实际位置可能不同,会导致坐标不准确 。为了解决这个问题,可以使用pyautogui.size()函数获取当前屏幕的分辨率,并根据分辨率调整坐标 。例如,假设你希望在屏幕中心进行点击操作,无论屏幕分辨率如何变化,都可以这样实现:
1 | import pyautogui |
异常处理
在使用 PyAutoGUI 时,可能会遇到各种异常情况 。除了前面提到的FailSafeException异常外,还可能遇到ImageNotFoundException异常,当使用locateOnScreen()等图像识别函数找不到指定图像时会抛出该异常 。你可以使用try - except语句来捕获并处理这些异常,使程序更加健壮 。例如:
1 | import pyautogui |
另外,在进行键盘输入操作时,如果目标窗口没有获得焦点,可能会导致输入内容没有出现在预期的位置 。为了避免这种情况,可以在执行键盘输入操作前,使用pyautogui.click()函数先将鼠标点击到目标窗口,使其获得焦点 。例如:
1 | import pyautogui |
通过合理运用这些使用注意事项与技巧,可以让你在使用 PyAutoGUI 进行自动化任务时更加得心应手,提高脚本的稳定性和可靠性 。
frp:一款强大的内网穿透代理工具
frp(Fast Reverse Proxy)是一款开源的高性能内网穿透代理工具,它允许你将位于NAT或防火墙后面的本地服务器暴露到公网上。frp支持TCP、UDP、HTTP和HTTPS协议,使得内部服务可以通过域名被外部访问。此外,frp还提供了P2P连接模式,进一步增强了其灵活性和可用性。
功能特点
frp以其简洁的设计和丰富的功能而闻名,以下是一些核心特性:
- 协议支持:支持TCP、UDP、HTTP和HTTPS协议,适用于多种网络环境。
- P2P连接:提供P2P连接模式,实现客户端间的直接通信,无需经过服务器。
- 配置灵活:支持TOML、YAML和JSON格式的配置文件,方便不同用户的需求。
- 安全性:支持Token和OIDC认证,增强连接的安全性。
- 性能优化:提供TLS加密和数据压缩,保障数据传输的安全和效率。
- 监控与日志:集成Prometheus监控,支持实时监控代理状态和流量。
- 负载均衡:支持通过分组实现简单的负载均衡。
- 健康检查:提供TCP和HTTP健康检查,确保服务的高可用性。
- 自定义域名:支持自定义子域名,方便在共享服务器上区分不同用户的服务。
- 插件系统:支持客户端和服务器端的插件扩展,增加了功能的灵活性和多样性。
安装
步骤1:访问GitHub Releases页面
打开浏览器,访问frp的GitHub Releases页面。
在页面中,找到最新发布的版本,这通常会被标记为“Latest”或有相应的版本号。
步骤2:下载二进制文件
根据你的操作系统(Windows、Linux或macOS)和架构(如x86_64、arm等),选择相应的预编译二进制文件。
- 对于Linux用户,你会找到以
linux_amd64或linux_arm64等命名的压缩文件。 - 对于macOS用户,文件名通常包含
darwin。 - 对于Windows用户,文件名会包含
windows_4.0。
点击相应的文件名,下载到你的计算机上。
步骤3:解压缩文件
解压缩下载的文件。对于Linux和macOS用户,可以使用tar命令:
1 | tar -zxvf frp_0.39.0_linux_amd64.tar.gz |
对于Windows用户,可以使用文件资源管理器或第三方解压缩软件解压.zip文件。
步骤4:移动到合适的目录
在解压缩的目录中,你会找到frps和frpc两个可执行文件,分别对应服务器端和客户端。
将frps和frpc移动到合适的目录,例如/usr/local/bin(需要管理员权限):
1 | sudo mv frps frpc /usr/local/bin/ |
步骤5:检查运行
在命令行中运行frps -v和frpc -v来检查二进制文件是否正确无误:
1 | frps -v |
这将显示frp的版本信息,确认安装成功。
示例用法
frp的使用涉及两个主要组件:frps(服务器端)和frpc(客户端)。以下是一些基本的示例用法,帮助你快速开始使用frp。
1. 通过SSH访问内网计算机
服务端(frps)配置和启动:
- 在拥有公网IP的服务器上配置
frps.toml:
1 | # frps.toml |
- 启动
frps:
1 | ./frps -c ./frps.toml |
客户端(frpc)配置和启动:
- 在内网计算机上配置
frpc.toml:
1 | # frpc.toml |
- 启动
frpc:
1 | ./frpc -c ./frpc.toml |
- 通过SSH访问内网计算机:
1 | ssh -p 6000 用户名@服务端公网IP |
2. 使用自定义域名访问内网Web服务
服务端(frps)配置和启动:
- 配置
frps.toml:
1 | # frps.toml |
- 启动
frps:
1 | ./frps -c ./frps.toml |
客户端(frpc)配置和启动:
- 配置
frpc.toml:
1 | # frpc.toml |
- 启动
frpc:
1 | ./frpc -c ./frpc.toml |
配置域名解析:
将www.example.com的A记录指向frps服务器的公网IP。访问Web服务:
通过浏览器访问http://www.example.com:8080。
这些示例仅展示了frp的一小部分功能。frp的灵活性和强大的功能使其成为内网穿透的有力工具。你可以根据具体需求调整配置,实现更复杂的网络穿透和代理需求。
Docker 国内镜像源配置指南
随着 Docker 的广泛应用,越来越多的开发者和企业开始使用 Docker 来构建和部署应用。然而,由于网络原因,直接从 Docker Hub 拉取镜像可能会遇到速度慢或者不稳定的问题。为了解决这一问题,本文将介绍如何配置国内镜像源,以加速 Docker 镜像的拉取速度。
为什么需要配置国内镜像源?
直接从 Docker Hub 拉取镜像可能会受到网络限制的影响,导致速度慢或者失败。配置国内镜像源可以有效地解决这一问题,提高镜像拉取的速度和稳定性。
配置步骤
以下是配置国内 Docker 镜像源的具体步骤:
1. 创建或修改 Docker 配置文件
在 Linux 系统中,你需要修改或创建 /etc/docker/daemon.json 文件。如果文件不存在,你可以使用以下命令创建它:
1 | sudo mkdir -p /etc/docker |
2. 重启 Docker 服务
修改配置文件后,需要重启 Docker 服务以使配置生效:
1 | sudo systemctl daemon-reload |
3. 验证配置是否成功
使用以下命令检查 Docker 信息,确认镜像源是否已经更改:
1 | docker info |
以上步骤可以帮助你配置国内镜像源,以加速 Docker 镜像的拉取速度。请根据实际情况选择可用的镜像源进行配置。这些镜像源均来自最新的搜索结果,确保了时效性。
Shell和Perl脚本加密与编译技术详解
在数字化时代,脚本编程在软件开发和自动化任务中扮演着至关重要的角色。然而,未加密的脚本代码面临着潜在的盗用和篡改风险,甚至可能导致敏感信息泄露。本文将探讨多种有效的脚本加密与编译技术,涵盖了Shell和Perl脚本的保护方法,旨在帮助开发者保护自己的代码和敏感信息。
Shell脚本加密与编译方法
使用shc工具
SHC(Shell Script Compiler)是一个开源工具,用于将Shell脚本编译成可执行文件。它将代码转换为C语言程序,然后再编译成二进制文件,以保护源代码。SHC的主要目的是提供一个简单的方式来保护Shell脚本代码,防止未经授权的访问和篡改。
- SHC的功能:SHC将Shell脚本编译成二进制可执行文件,隐藏脚本的实现细节,并在编译过程中对脚本内容进行预处理和加密。
安装SHC
通过包管理器安装SHC(推荐):
1 | # Ubuntu/Debian: |
从源代码编译安装:
1 | 安装必要的编译工具和库。包括 `gcc`(GNU C编译器)和 `make` 工具: |
编译示例
脚本(hello.sh):
1 | #!/bin/bash |
编译脚本:
1 | shc -f hello.sh |
将生成两个文件:hello.sh.x(可执行文件)和hello.sh.x.c(C源文件)。
执行编译文件:
1 | ./hello.sh.x |
加密与编码
除了使用shc工具,还可以使用base64编码或openssl加密来增加脚本的安全性。
使用base64编码将脚本内容进行base64编码,并在运行时解码执行:
1 | # 编码 |
使用openssl工具对脚本进行对称或非对称加密,然后在运行时解密。例如:
1 | # 加密 |
Perl脚本加密与编译方法
PAR::Packer工具
PAR::Packer是一个Perl模块,用于将Perl脚本及其所有依赖打包成可执行的二进制文件。它分析Perl脚本,自动识别所用到的模块,并将这些模块打包在内,确保在目标环境中运行时可以找到。
- 安装并使用:
1 | # 以使用 CPAN 安装: |
perlcc编译器
perlcc是Perl语言的一个编译器,它可以将Perl脚本编译成C代码,然后进一步编译成可执行的二进制文件。然而,perlcc可能无法处理某些复杂的Perl特性或者特定模块,导致编译失败。
- 编译过程示例:
1 | perlcc -o task_manager task_manager.pl |
使用-d选项可以在编译时显示调试信息:
1 | perlcc -d -o hello hello.pl |
查看perlcc的更多选项和功能,可以使用以下命令:
1 | perlcc -h |
加密与解密技术
使用Crypt::CBC模块可以实现对数据的加密和解密。Crypt::CBC提供了基于块密码的加密和模式,常用的加密算法包括AES、DES等。
- 安装Crypt::CBC:
1 | cpan Crypt::CBC |
使用Crypt::CBC模块加密一个Perl脚本,涉及到定义一个加密的过程并将脚本本身保存为一个密文,然后可以在运行时解密并执行。这种做法只是为了保护源代码,这并不是一种绝对的安全措施,因为熟悉Perl的人仍然可以通过逆向工程等手段获取原始代码。
以下是使用Crypt::CBC加密和解密Perl脚本的示例代码:
加密脚本(encrypt_script.pl):
1 | !/usr/bin/perl |
解密并执行脚本(run_encrypted.pl):
1 | !/usr/bin/perl |
运行解密并执行的脚本:
1 | perl run_encrypted.pl |
总结
脚本加密和编译技术为确保源代码安全性提供了有效的手段。本文详细介绍了使用流行工具和方法对Shell脚本和Perl脚本进行加密和编译的步骤,旨在帮助开发者保护自己的代码和敏感信息。
利用 Rust 构建轻量级多端桌面应用:Pake 介绍
Pake 是一个基于 Rust 的工具,它允许开发者轻松构建轻量级的多平台桌面应用。以其小巧的体积和卓越的性能,Pake 成为了许多开发者的首选工具。本文将详细介绍 Pake 的特性、安装方法、使用指南以及如何进行定制开发,并特别强调快捷键的使用。
Pake 的特性
Pake 的核心特性包括:
- 体积小:相比传统的 Electron 套壳打包,Pake 的体积小将近 20 倍,大约在 5M 左右。
- 性能优异:Pake 的底层使用的是 Rust Tauri 框架,相较于 JavaScript 框架,它提供了更轻快的性能体验和更小的内存占用。
- 功能丰富:Pake 不仅能打包应用,还实现了快捷键透传、沉浸式窗口、拖动、样式改写、去广告等功能,并支持产品的极简风格定制。
- 简单易用:Pake 被描述为一个简单的小玩具,使用 Tauri 替代了传统的套壳网页打包思路,同时推荐使用 PWA(Progressive Web Apps)。
开始使用 Pake
安装 Pake CLI
Pake 提供了命令行工具,可以通过 npm 进行安装:
1 | npm install -g pake-cli |
命令行一键打包
使用 Pake 进行一键打包非常简单,以下是基本的命令使用示例:
1 | pake url [OPTIONS]... |
例如,如果你想打包 Weekly 应用,并隐藏标题栏,可以使用以下命令:
1 | pake https://weekly.tw93.fun --name Weekly --hide-title-bar |
快捷键说明
Pake 支持快捷键,以提高用户的工作效率。以下是 Pake 支持的快捷键及其功能:
| Mac | Windows/Linux | 功能 |
|---|---|---|
| ⌘ + [ | Ctrl + ← | 返回上一个页面 |
| ⌘ + ] | Ctrl + → | 去下一个页面 |
| ⌘ + ↑ | Ctrl + ↑ | 自动滚动到页面顶部 |
| ⌘ + ↓ | Ctrl + ↓ | 自动滚动到页面底部 |
| ⌘ + r | Ctrl + r | 刷新页面 |
| ⌘ + w | Ctrl + w | 隐藏窗口,非退出 |
| ⌘ + - | Ctrl + - | 缩小页面 |
| ⌘ + + | Ctrl + + | 放大页面 |
| ⌘ + = | Ctrl + = | 放大页面 |
| ⌘ + 0 | Ctrl + 0 | 重置页面缩放 |
高级使用
Pake 的代码结构和高级用法可以在其官方文档中找到。以下是一些关键点:
- 修改 src-tauri 目录下的 pake.json 中的 url 和 productName 字段,并同步修改 tauri.config.json 中的 domain 字段。
- 修改 tauri.xxx.conf.json 中的 icon 和 identifier 字段,图标可以从 icons 目录选择,或者从 macOSicons 下载。
- 在 pake.json 中修改窗口属性,如 width/height、fullscreen、resizable 等。
- 适配 Mac 沉浸式头部,可以将 hideTitleBar 设置为 true,并为 Header 元素添加 padding-top 样式。
结语
Pake 是一个强大的工具,它让构建轻量级多端桌面应用变得简单快捷。无论是小白用户、开发用户还是折腾用户,都能在 Pake 中找到适合自己的使用方式。希望这篇文章能帮助你更好地了解和使用 Pake,享受构建桌面应用的乐趣。
修复 PHP 文件中的 Shebang 行错误
问题描述
在 Linux 系统中,我们经常使用 Shebang(#!)行来指定脚本的解释器。对于 PHP 脚本,我们通常会在文件开头写上 #!/usr/bin/env php。然而,有时候即使命令行能够识别php 指令,使用 Shebang 行时却会报错 “No such file or directory”。这通常是因为文件的编码格式问题。
解决方案
步骤 1: 检查文件编码
首先,我们需要检查文件的编码格式。在 Linux 系统中,我们可以使用 vim 编辑器来查看和修改文件的编码格式。
- 打开终端。
- 输入
vim yourfile.php命令来打开你的 PHP 文件。 - 在
vim中,输入:set ff命令来查看文件的格式。
步骤 2: 修改文件编码
如果 :set ff 命令的输出显示 fileformat=dos,那么你需要将文件格式更改为 unix。
- 在
vim中,输入:set ff=unix命令来更改文件格式。 - 按下 Esc 键退出命令模式。
- 输入
:wq命令保存更改并退出vim。
步骤 3: 验证更改
更改文件编码后,再次尝试运行你的 PHP 脚本。如果 Shebang 行不再报错,那么问题已经解决。
MarkText:下一代Markdown编辑器的新星
在数字时代,我们每天都在产生和消费大量的文本内容。无论是撰写报告、编写文档、还是记录个人笔记,一个高效、简洁且功能丰富的文本编辑器都是我们不可或缺的工具。今天,我要向大家介绍一款名为MarkText的开源Markdown编辑器,它以其出色的性能和优雅的设计,成为了文本编辑领域的一颗新星。
MarkText简介
MarkText是一款开源的Markdown编辑器,专注于速度和可用性。它支持多个操作系统,包括Linux、macOS和Windows,让不同平台的用户都能享受到流畅的写作体验。MarkText以其简洁的界面和实时预览功能,为用户提供了一种无干扰的写作环境,使得写作变得更加专注和高效。
核心特性
MarkText拥有许多令人印象深刻的特性,以下是其中的一些亮点:
实时预览:MarkText提供了所见即所得的实时预览功能,这意味着你在编辑器中输入的内容会立即反映在预览窗口中,让你可以即时看到最终的排版效果。
遵循Markdown规范:它支持CommonMark规范和GitHub Flavored Markdown规范,这意味着你可以使用MarkText来编写符合行业标准的Markdown文档。
Markdown扩展:除了标准的Markdown功能,MarkText还支持数学表达式(通过KaTeX)、front matter和emoji等Markdown扩展,丰富了你的写作选项。
样式快捷方式:MarkText提供了段落和内联样式的快捷方式,帮助你提高写作效率。
输出格式多样:你可以将文档输出为HTML和PDF文件,满足不同场景的需求。
主题丰富:MarkText提供了多种主题,如Cadmium Light、Material Dark等,用户可以根据自己的喜好选择不同的主题。
编辑模式多样:包括源代码模式、打字机模式和专注模式,适应不同用户的写作习惯。
图片粘贴:直接从剪贴板中粘贴图片,简化了图片插入的过程。
下载与安装
MarkText的安装非常简单。对于macOS用户,你可以通过Homebrew-Cask安装:
brew install --cask mark-text
Windows用户可以下载安装向导并运行,或者使用Chocolatey和Winget等软件包管理器进行安装:
choco install marktext
或者
winget install marktext
Linux用户则可以按照官方提供的安装指南进行操作。
最新版本下载
想要获取MarkText的最新版本,你可以直接访问其GitHub发布页面:
MarkText GitHub Releases
在这里,你可以找到适用于不同操作系统的安装包,选择适合你的版本进行下载和安装。
PHP 调用 MongoDB 全解析
PHP 调用 MongoDB 全解析
MongoDB 是一款流行的开源文档型数据库,它以 JSON 风格的文档形式存储数据,具有高性能、高可扩展性和灵活的数据模型等特点。而 PHP 作为一种广泛应用于 Web 开发的脚本语言,与 MongoDB 结合可以为开发者提供强大的数据存储和处理能力。本文将详细介绍如何使用 PHP 调用 MongoDB 进行数据的增删改查等操作。
环境准备
在使用 PHP 调用 MongoDB 之前,需要确保已经安装了 MongoDB 数据库和 PHP 的 MongoDB 扩展。可以使用 Composer 来安装 MongoDB 的 PHP 驱动,在项目根目录下创建一个composer.json文件,内容如下:
json
1 | { |
然后在终端中执行composer install命令来安装依赖。
代码示例与解析
连接 MongoDB
1 |
|
上述代码首先通过require 'vendor/autoload.php';引入 Composer 的自动加载文件,然后使用MongoDB\Client类来连接本地的 MongoDB 服务器,端口为27017。接着指定了要使用的数据库test和集合users。
插入数据
插入单条数据
1 | $collection->insertOne([ |
使用insertOne方法可以向集合中插入一条数据,数据以关联数组的形式传入。
指定 ID 插入数据
1 | $collection->insertOne([ |
在插入数据时,可以手动指定_id字段,使用MongoDB\BSON\ObjectID类来创建一个 ObjectID 对象。
插入多条数据
1 | $collection->insertMany([ |
使用insertMany方法可以一次性插入多条数据,传入一个二维数组,每个子数组代表一条数据。
查询数据
查询单条数据
1 | $document = $collection->findOne([ |
使用findOne方法可以查询符合条件的第一条数据,返回一个文档对象,使用json_encode方法将其转换为 JSON 字符串并输出。
查询多条数据
1 | $cursor = $collection->find([ |
使用find方法可以查询符合条件的多条数据,返回一个游标对象,通过foreach循环遍历游标对象,输出每条数据。
查询指定数量的数据
1 | $cursor = $collection->find([ |
在find方法的第二个参数中,可以使用limit选项来指定查询结果的数量。
条件查询
1 | // 查询年龄大于18的数据 |
在查询条件中,可以使用 MongoDB 的查询操作符,如$gt(大于)、$lt(小于)、$exists(是否存在)等。
排序查询
1 | $cursor = $collection->find([ |
在find方法的第二个参数中,可以使用sort选项来对查询结果进行排序,1表示正序,-1表示倒序。
修改数据
查询并修改
1 | $cursor = $collection->findOneAndUpdate([ |
使用findOneAndUpdate方法可以查询符合条件的第一条数据并进行修改,返回修改前的文档对象。
更新数据
1 | $collection->updateOne([ |
使用updateOne方法可以更新符合条件的第一条数据,使用$set操作符来指定要更新的字段和值。
查询并替换
1 | $cursor = $collection->findOneAndReplace([ |
使用findOneAndReplace方法可以查询符合条件的第一条数据并进行替换,返回替换前的文档对象。
存在更新不存在插入
1 | $collection->updateOne([ |
在updateOne方法的第三个参数中,使用upsert选项设置为true,可以实现如果符合条件的数据存在则更新,不存在则插入的功能。
更新多条数据
1 | $collection->updateMany([ |
使用updateMany方法可以更新符合条件的多条数据。
删除数据
删除单条数据
1 | $collection->deleteOne([ |
使用deleteOne方法可以删除符合条件的第一条数据。
删除多条数据
1 | $collection->deleteMany([ |
使用deleteMany方法可以删除符合条件的多条数据。
删除集合和数据库
1 | // 删除集合 |
使用drop方法可以删除集合和数据库。